
You thought you knew how Google ranks content. Then, the unthinkable happens — a leaked document blows the lid off everything.
On March 13, 2024, thousands of Google API documents were published on GitHub revealing some of the most important elements that Google Search uses to rank content.
Now we finally get a glimpse of the inner workings of Google’s ranking algorithm, based on the analysis of Rand Fishkin of SparkToro and Michael King of iPullRank.
Table Of Contents:
- Google Search Document Leak Reveals Ranking Factors
- The Significance of Links and Entities
- Leveraging Chrome Data for SEO
- Implications for Exact Match Domains and Product Reviews
- Ranking Systems
- Role of Machine Learning in Google’s Algorithm
- Conclusion
Google Search Document Leak Reveals Ranking Factors
The Google Search document leak has sent shockwaves through the SEO community. It’s one of the biggest stories to hit the industry in years, giving us a rare glimpse into how Google’s ranking algorithm works.
The leaked documents don’t spell out how Google scores or ranks content, but they offer much info about content, links, and user interactions.
Not all these features are necessarily ranking factors — some might be, some might not. One thing we don’t know about these features is how they’re weighted in Google’s ranking system.
Are they outdated or still in play? It’s unclear.
But this is big news for SEOs who have been trying to figure out Google’s ranking factors for years.
According to the leaked documents, we have more data about some features, including:
- Clicks: How users interact with search results
- Links: The quality and relevance of inbound links
- Content: The relevance and quality of on-page content
- Entities: The recognition and understanding of named entities
- Chrome Data: User behavior data collected from Chrome users
This confirms much of what SEOs have long suspected, but it’s still eye-opening to see it spelled out in black and white.
As an SEO with over a decade of experience, I can tell you that these leaked documents are a treasure trove of insights. They shed light on some of the more vague aspects of Google’s algorithm, including:
- User engagement signals are critical. Google is paying close attention to how users interact with search results, including clicks, bounce rates, and dwell time.
- Links still matter, but relevance is key. It’s not just about the quantity of links, but also the quality and relevance of the linking sites.
- Content quality and relevance are more important than ever. Google is getting better at understanding the actual content of web pages, not just the keywords.
- Entities are playing a bigger role in search. Google is using named entity recognition to determine whether an entity is the author of the document.
Key Takeaways from the Leaked Documents
So what are the key takeaways from this document leak? Here are some key factors that were analyzed:
Number of Modules and Features:
- The leaked API documentation has information about 2,596 modules. These modules have a total of 14,014 attributes, which are like features or characteristics.
- The modules relate to various parts of Google services like YouTube, Assistant, Books, video search, links, web documents, and more. Google’s systems use a “monorepo,” meaning all the code is stored in one place and any machine on the network can access it.

Types of Modules:
- The leaked documentation explains each module and breaks them down into summaries, types, functions, and attributes. It mainly describes property definitions for protocol buffers (protobufs), which are used across ranking systems for search engine result pages (SERPs).

Domain Authority
- Despite Google’s denial, the leaked documentation shows that Google does have a metric called “siteAuthority.” This metric measures the authority or importance of a website for a specific topic. We don’t know exactly how Google calculates or uses this metric, but it’s clear it exists and influences search rankings.

Click Usage
- Google representatives have denied using clicks as a ranking factor. However, in the U.S. vs. Google Antitrust Trial in 2023, Pandu Nayak revealed that Google had been using the NavBoost and Glue ranking systems to adjust rankings since 2005. Glue relates to universal search, while NavBoost focuses on web search, updated to use 13 months of data.
- Patents such as the 2007 Time-Based Ranking patent show that Google has been using click data to adjust search results for years.
- NavBoost has a module specifically focused on click signals, including metrics like bad clicks, good clicks, and dwell time.
- Google leverages click data to prevent manipulation.
- Click-based measurements also affect indexing signals and content decay.
- User clicks are represented as votes.
- Google counts bad clicks and segments data by country and device.
- Long clicks, where users spend a significant amount of time on a page, are considered successful search sessions.

NavBoost as a Strong Signal:
- NavBoost is a critical ranking signal for Google.
- The leaked documentation mentions NavBoost multiple times and shows it’s used at different levels of a website.
- While Google doesn’t mention “CTR” or “dwell time” in the documentation, the evidence suggests they use click and post-click behavior as ranking factors
- Google uses clicks and post-click behavior in its ranking algorithms.
Sandbox:
- Despite Google representatives having denied the existence of a “sandbox” where new websites are segregated based on age or lack of trust signals, the leaked documentation reveals the presence of an attribute called “hostAge,” which is used to identify and handle fresh spam during serving time.
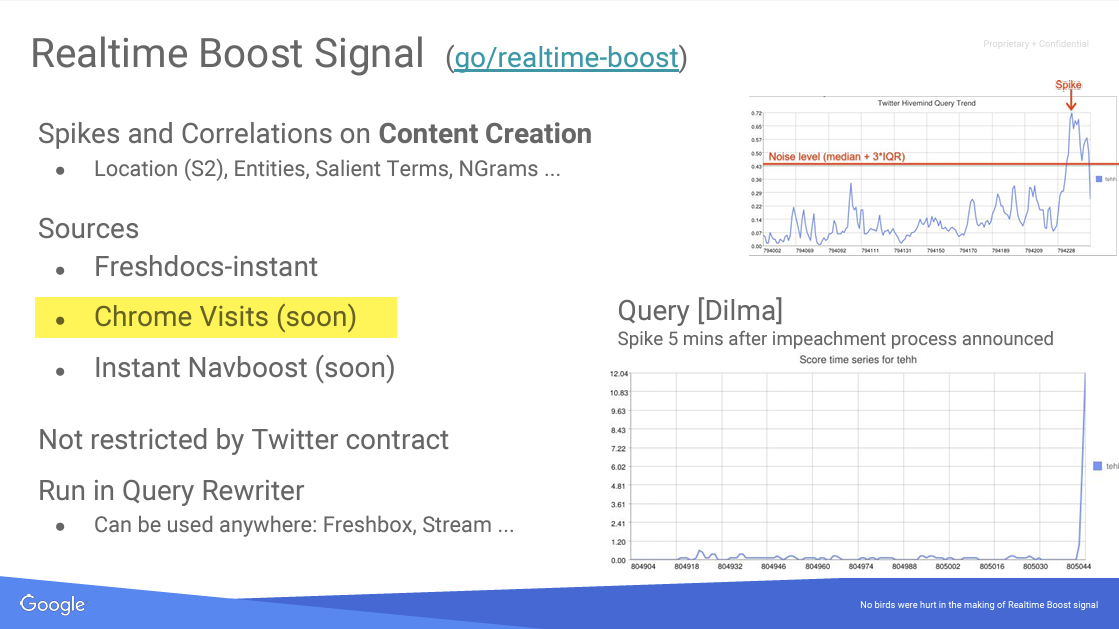
Chrome Data for Ranking:
- Modules related to page quality and sitelinks contain attributes related to views from Chrome, indicating that Chrome data is indeed considered for ranking purposes.
The Significance of Links and Entities
Two of the most important features highlighted in the leaked documents are links and entities.
Google’s internal content API warehouse is used to analyze link patterns and assess the authority and trustworthiness of linking websites. Some of the key factors that Google looks at include:
- The relevance of the linking page to the linked page
- The authority and trustworthiness of the linking domain
- The anchor text used in the link
- The placement and context of the link on the page
To earn high-quality links, focus on creating valuable content that naturally attracts links from relevant and authoritative sites in your niche.
Leveraging Chrome Data for SEO
One of the more surprising revelations from the leaked documents is the extent to which Google uses Chrome user data to inform its ranking algorithm.
According to the documents, Google collects a wide range of user behavior data from Chrome, including:
- Browsing history
- Click data
- Dwell time
- Bounce rates
- Scroll depth
This data is used to understand how users interact with web pages and search results, which can then influence rankings.
For example, if a page has a high click-through rate from search results but also a high bounce rate, that could be a signal to Google that the page isn’t meeting user expectations.
Implications for Exact Match Domains and Product Reviews
Finally, let’s take a look at two specific areas that were called out in the leaked documents: exact match domains and product reviews.
Future of Exact Match Domains in Light of the Leak
The leaked documents suggest that Google may be cracking down on exact match domains (EMDs) – domains that exactly match a target keyword.
While EMDs used to be a popular tactic for ranking quickly for specific keywords, Google has been devaluing them in recent years. The leaked documents suggest that this trend will continue, with Google placing more emphasis on the quality and relevance of content rather than the domain name itself.
If you’re considering an EMD for a new site, I would advise against it. Instead, focus on choosing a brandable, memorable domain name that reflects your business or content.
Ensuring High-Quality Product Review Content
Another area that was specifically mentioned in the leaked documents is product reviews. Google appears to be placing a greater emphasis on the quality and authenticity of product reviews when determining search rankings.
To ensure your product review content is up to par, focus on creating in-depth, unbiased reviews that provide genuine value to users. Use your own photos and videos to add authenticity, and disclose any sponsored relationships or affiliate links.
Ranking Systems
Here is the list of some ranking systems and their functions:
Crawling
Trawler – This is Google’s web crawling system. It has a crawl queue, maintains crawl rates, and analyzes how often pages change.
Indexing
- Alexandria – This is Google’s core indexing system.
- SegIndexer – This segregates documents into tiers within the index.
- TeraGoogle – This secondary indexing system stores documents that live on disk long term.
Rendering
HtmlrenderWebkitHeadless – This is Google’s rendering system for JavaScript pages which uses Headless Chrome.
Processing
- LinkExtractor – This algorithm extracts links from pages.
- WebMirror – This system is in charge of managing duplication and canonicalization.
Ranking
- Mustang – This is the primary scoring, ranking, and serving system of Google.
- Ascorer – This is the primary ranking algorithm that ranks pages before any re-ranking adjustments.
- NavBoost – This algorithm re-ranks pages based on click logs of user behavior.
- FreshnessTwiddler – This algorithm re-ranks pages based on freshness.
- WebChooserScorer – This algorithm defines feature names in snippet scoring.
Serving
- Google Web Server – This is the front-end server that provides Google with payloads of data to display to the user.
- SuperRoot – This is the brain behind Google Search that sends messages to Google’s servers for re-ranking and presenting results.
- SnippetBrain – This is the algorithm that generates snippets for search results.
- Glue – This system pulls together universal results based on user behavior.
- Cookbook – This is Google’s system for generating signals where values are created at runtime.
Role of Machine Learning in Google’s Algorithm
One of the most significant takeaways from the leaked documents is the growing role of machine learning in Google’s ranking algorithm.
Systems like RankBrain and neural matching are becoming increasingly important in helping Google understand the intent behind queries and match them with the most relevant results.
As Google’s algorithm becomes more sophisticated, it’s moving away from simple keyword matching and towards a more holistic understanding of content and user intent.
For SEOs, this means focusing less on individual keywords and more on creating comprehensive, high-quality content that satisfies user needs.
Adapting SEO Tactics Based on the Leaked Information
Based on the leaked information, here are some SEO tactics that I recommend:
- Focus on user engagement metrics. Track and optimize for metrics like click-through rate, bounce rate, and dwell time.
- Prioritize link relevance over quantity. Earn links from high-quality, relevant sites in your niche.
- Create in-depth, topically-relevant content. Cover topics comprehensively and use named entities to help Google determine authorship.
- Optimize for featured snippets and other SERP features. Use structured data and clear page layouts to make your content more accessible to Google.
Importance of Diversifying Content Strategies
In addition to adapting your SEO tactics, it’s also important to diversify your content strategies. Relying too heavily on any one tactic is risky in today’s ever-changing search landscape.
Instead, focus on creating a well-rounded content strategy that includes:
- Blog posts and articles
- Videos and visual content
- Interactive tools and resources
- Social media and community building
- Email marketing and lead generation
By diversifying your content, you’ll be better positioned to weather any future algorithm updates or shifts in user behavior.
Conclusion
The Google Search document leak is a game-changer. It’s confirmed what many of us suspected – that there is indeed a Google sandbox and that Google uses domain authority, clicks, and Chrome data to rank content.
But more than that, it’s given us a roadmap. We now know the key factors that influence rankings, and we can use that knowledge to create content that truly resonates with both users and search engines.


